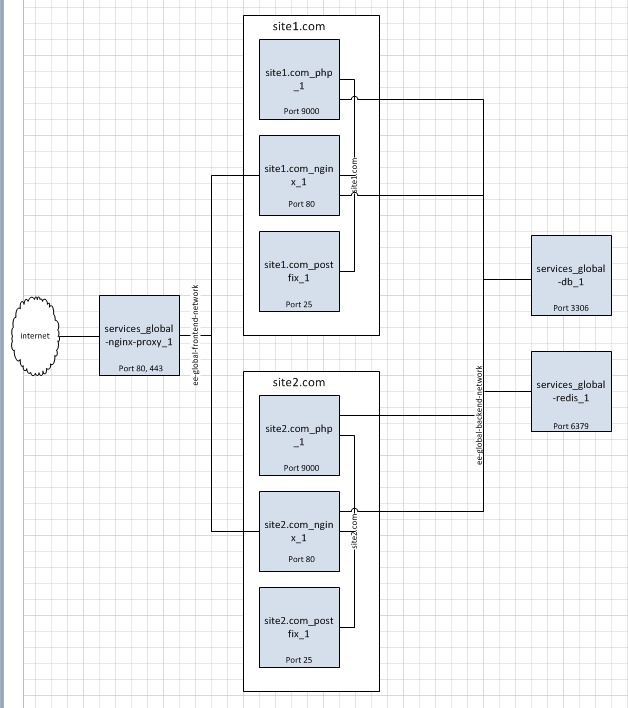
After running ee cli update to upgrade from version 4.0.10 to 4.0.12 the site is no longer accessible. No response from the server to either the url https://dev.brightray.com/ or the direct IP address. Both the URL and IP address respond to ping but the web service doesn’t seem to be responding.
No visible errors during the upgrade. It came back saying successfully upgraded. After a reboot, the server came back up without issue but no response to web requests. I can telnet into the system, attempted to restart the services, watched the logs. No messages show up on the logs when trying to access either the site or the direct IP address.
System Information
- ee cli info
+-------------------+----------------------------------------------------------+
| OS | Linux 4.15.0-47-generic #50-Ubuntu SMP Wed Mar 13 10:44: |
| | 52 UTC 2019 x86_64 |
| Shell | /bin/bash |
| PHP binary | /usr/bin/php7.2 |
| PHP version | 7.2.17-1+ubuntu18.04.1+deb.sury.org+3 |
| php.ini used | /etc/php/7.2/cli/php.ini |
| EE root dir | phar://ee.phar |
| EE vendor dir | phar://ee.phar/vendor |
| EE phar path | /root |
| EE packages dir | |
| EE global config | /opt/easyengine/config/config.yml |
| EE project config | |
| EE version | 4.0.12 |
+-------------------+----------------------------------------------------------+
- lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 18.04.2 LTS
Release: 18.04
Codename: bionic
- docker version
Client:
Version: 18.09.4
API version: 1.39
Go version: go1.10.8
Git commit: d14af54266
Built: Wed Mar 27 18:35:44 2019
OS/Arch: linux/amd64
Experimental: false
Server: Docker Engine - Community
Engine:
Version: 18.09.4
API version: 1.39 (minimum version 1.12)
Go version: go1.10.8
Git commit: d14af54
Built: Wed Mar 27 18:01:48 2019
OS/Arch: linux/amd64
Experimental: false
- docker-compose version
docker-compose version 1.23.2, build 1110ad01
docker-py version: 3.6.0
CPython version: 3.6.7
OpenSSL version: OpenSSL 1.1.0f 25 May 2017